在之前的文章中,提到关于百度的搜索源码可以做哪些事情:http://www.zhangte.org/python/125.html
这里实践一下这个完整的过程
首先,爬虫部分不说,各种实现方式都可以,核心就在于,要把百度的搜索结果完整的保存下来! 我这里暂时以百度Json版的结果为例,比如这样: 这里圈起来的核心数据:
其实这样保存,爬虫也方便,查询也方便,何乐不为,而且想干嘛就干嘛,自由灵活度又高...,而且不需要频繁请求百度,对ip
......
点击阅读更多...
注意:遵守《互联网资讯信息服务管理规定》,广告性质的评会被删除,相关违规ID会被永久封杀。

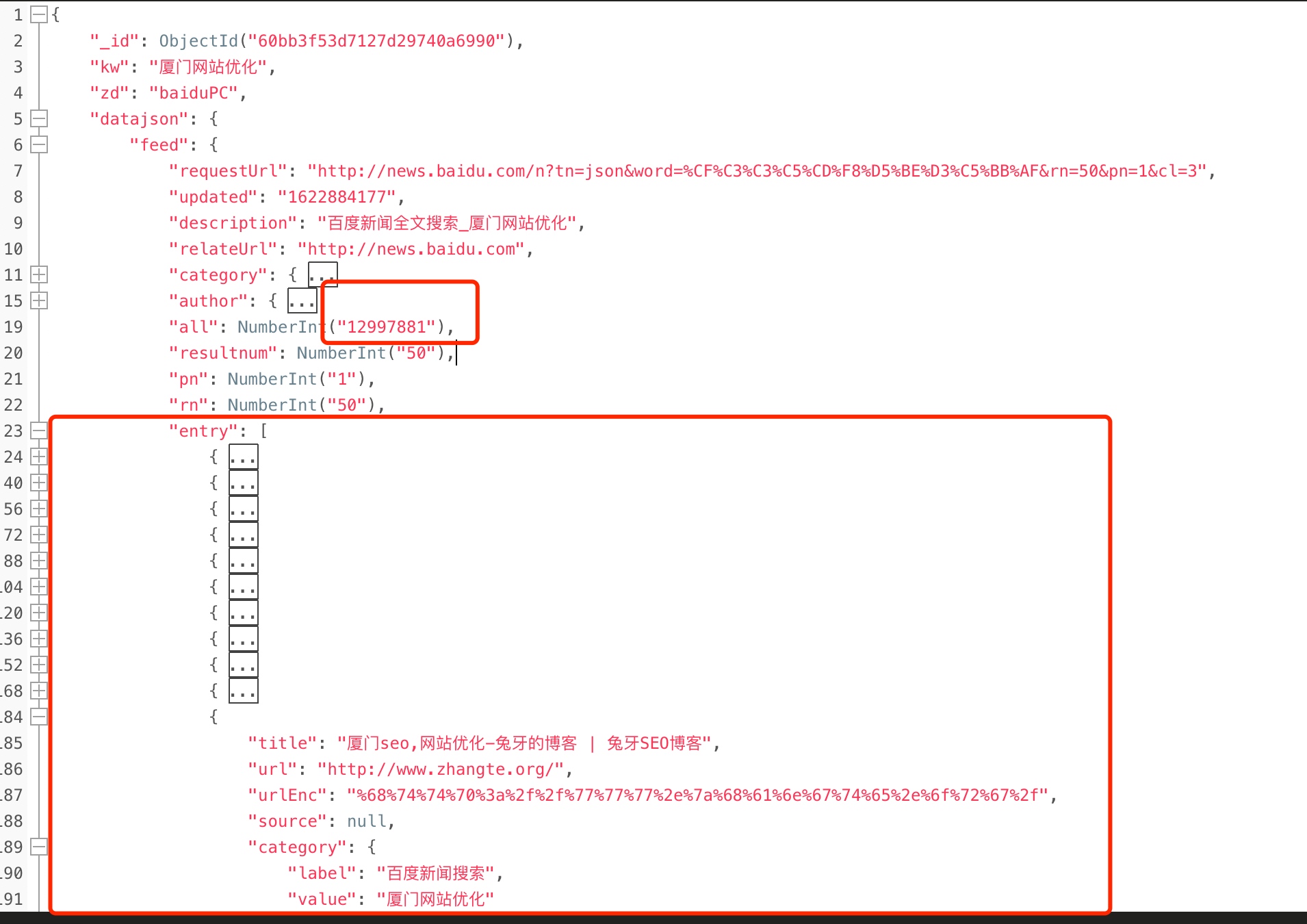 这里圈起来的核心数据:
这里圈起来的核心数据:




